Object detection is a very well-studied subject, which is used in many useful and exciting applications today, such as for tracking objects (speed, position etc.), in surveillance system, for anomaly detection, for sorting and filtering objects on assembly lines, for counting (e.g. how many people are visiting the central station every day and how many cars are passing by this bridge or intersection) and many others.
In this post, we are going to try to answer the following two question:
- What is object detection?
- How do object detectors learn to detect objects?
One of the key ideas about how object detectors, and really any type of deep learning model, learn is loss functions. The loss function is the very thing which defines what deep learning models such as object detectors will learn during training. So this is what we are going to cover in this post. More specifically, we are going to take a look at the two main loss functions of object detectors called bounding box regression and cross-entropy loss.
For clarification, loss functions are sometimes also being referred to as objective functions or cost functions. However, in this post we will stick to loss functions.
1. What is Object Detection?
Before we go into the details of loss functions, let’s first consider what object detection is and what the goal of object detectors are. The concept of object detection is visualized in figure 1 and can be summarized into the following two tasks:
- Localize objects (Where are the objects in the image?)
- Classify objects (What kind of object is it? Is it a cat, a car, a human?)
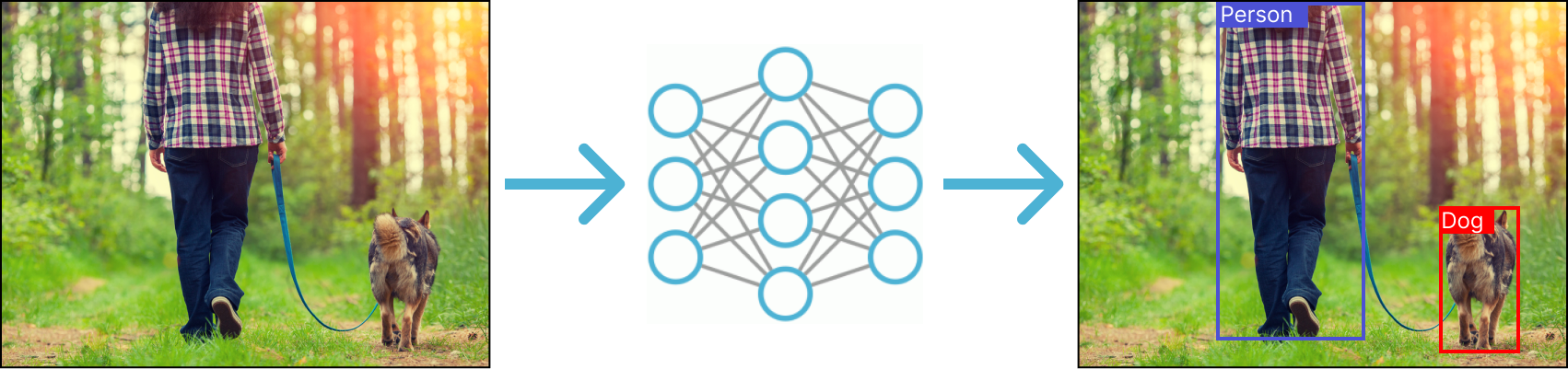 Figure 1: A bird-eye view of an object detection pipeline. An image is inputted into an object detection. The object detector outputs predictions - bounding boxes and class predictions
Figure 1: A bird-eye view of an object detection pipeline. An image is inputted into an object detection. The object detector outputs predictions - bounding boxes and class predictions
Localizing objects
Object detector models typically uses bounding boxes to denote the location of an object. It actually only takes four integers to represent a bounding box: (x1, y1)-coordinate which specifies the bounding box’s upper-left corner and a (x2, y2)-coordinate which specifies it’s lower-right corner. An example of a bounding box can be seen in figure 2.
 Figure 2: An image with a bounding box represented by it’s (x1, y1)-coordinates and (x2, y2)-coordinates.
Figure 2: An image with a bounding box represented by it’s (x1, y1)-coordinates and (x2, y2)-coordinates.
Classifying Objects
Once an object detector models has localized an object, the next thing it needs to do is guess what class the object belongs to. Is it a person? Is it a tree? etc. The object detector does this by considering the pixels in the region of the localized object. Concretely, the model tries to predict a probability for each of the classes the object detector is being trained to identify. Say the object detector is being trained to detect men and women, the model will then output a probability for woman and man for at each localized object. An example of this is shown in figure 3.

Figure 3: An image with two predictions. For each prediction the object detector model calculates a probability for each of the classes it is learning to detect. In this example the model is learning to detect men and woman.
2. How do object detectors learn to detect objects?
Now we have touched upon the basic tasks of object detectors, which was to localize and classify objects in images. But how does the object detection model actually learn how to solve these tasks? This is done through training!
Training
An object detection model is trained by feeding it with lots of annotated images, where annotations means bounding boxes with assigned classes, specified by a human annotator. These annotations are also referred to as the ground truths. An example of a ground truth bounding box can be seen in figure 4.

Figure 4: An image used for training an object detector. The image has been annotated with a ground truth bounding box by a human annotator.
In the beginning of the training, the model will have no idea how to detect objects, but it will gradually learn to do so, because it’s internal parameters (weights and biases) are adjusted every time it makes prediction mistakes.
The more mistakes the model make, the more it’s parameters are adjusted. But in order to determine the seriousness of mistakes, we have to figure out a way to quantify the mistakes.
This is where the loss function come into the picture. The loss function measure how serious the mistakes of the object detector is by quantifying the mistakes into a number. The loss function of object detectors is a combination of two individual loss functions:
- Bounding Box Regression (Which will measure how well predicted bounding boxes captures ground truth bounding boxes)
- Cross Entropy Loss (Which will measure how good a job the detector did in predicting the correct class)
Bounding Box Regression
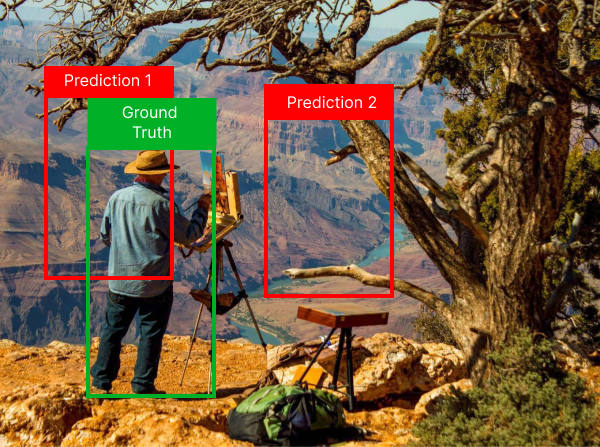
Let’s see what bounding box regression is through an example. In figure 5, we see two predictions proposed by the object detector. None of the predictions quiet capture the person object in the image. But which of the predictions do you think is better and why is it better? It’s prediction 1 of course and It’s better because it captures the person object better than prediction 2.

Figure 5: two predictions proposed by an object detector. Prediction 1 is a better prediction, because it captures the person better than prediction 2.
Bounding Box regression is a metric for measuring how well predicted bounding boxes captures objects. This is done by calculating the mean-squared error (MSE) between the coordinates of predicted bounding boxes and the ground truth bounding boxes.

Figure 6: Two predicted bounding boxes (red) proposed by an object detection and a ground truth bounding box (green) annotated by a person. Bounding box regression loss is used for measuring how close detected bounding boxes are to ground truth bounding boxes.
Let’s try calculating the bounding box regression value for the two predictions and ground truth bounding boxes in figure 6. The MSE between two bounding boxes, P and Q is given by:
Where 4 comes from the fact that we want the mean of 4 coordinates (x1, y1, x2, y2). For the two predictions we get the following MSE values:
| x1 | y1 | x2 | y2 | |
|---|---|---|---|---|
| Ground Truth (Q) | 100 | 150 | 250 | 300 |
| Prediction 1 (P1) | 50 | 75 | 200 | 225 |
| Prediction 2 (P2) | 300 | 120 | 500 | 310 |
As can be seen in the table the MSE is much bigger for prediction 2 than for prediction 1. The bounding box regression loss is what we get when we take the sum of all the MSE for all the matched detection- and ground truth bounding boxes.
Cross-Entropy Loss
Now let’s consider the second part of the combined object detection loss function, which is called cross-entropy loss. At first, cross-entropy loss might sound complex and confusing. In fact, Cross-entropy is sometimes also called negative log loss, which might sound even more complex. But through an example, we will see that cross-entropy loss is really just a metric for measuring how good a job the object detector does at predicting the correct classes at the location of the predicted bounding boxes.
As previously mentioned, the object detector will try to predict a probability for each class at a predicted bounding box location. This probability can also be thought of as the model’s confidence. The higher the probability the more confident the model is, that a given localized object belongs to some class. Let’s consider the predictions and ground truths in figure 7.

Figure 7: two predictions made by an object detector (red) and two ground truth bounding boxes annotated by a human annotator (green). Prediction 1 matches ground truth 1 and prediction 2 matches ground truth 2.
The object detector has calculated a probability for how confident it is in each of the classes, woman and man, for each predicted bounding box. The model is 90% confident that prediction 1 is a woman and 65% confident that prediction 2 is a woman.
The predictions are not bad, but especially prediction 2, has a low prediction confidence of only 65%. From the annotated ground truths we know there is, with 100% certainty, a woman at the location.
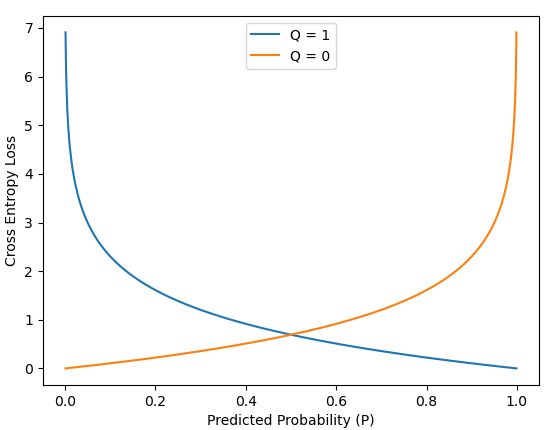
One way of calculating how well the object detector predicted the class would be to calculate the absolute difference between the predicted probability and the actual (e.g. loss of 100%-90%=10 for prediction 1 and 100%-65%=35 for prediction 2). Another way, is through cross-entropy. Cross-entropy gives a smoother loss, which penalizes big differences a lot and small difference a little. Cross-entropy loss between a ground truth probability, p, and a predicted probability, q, is given by the following equation:
From the equation it might not be clear what this function looks like given two probabilities. But the equation gives the following plot if Q=100%=1.0 and Q=0%=0.0:
Let’s use the example from figure 7 to calculate the cross-entropy loss for each of the matched predictions and ground truths:
| woman | man | |
|---|---|---|
| Ground Truth 1 (Q1) | 100% | 0 |
| Prediction 1 (P1) | 90% | 10% |
| woman | man | |
|---|---|---|
| Ground Truth 2 (Q2) | 100% | 0 |
| Prediction 2 (P2) | 65% | 35% |
As can be seen from the calculations the cross-entropy loss is much bigger for prediction 2 and ground truth 2 than for prediction 1 and ground truth 1 due to the fact that prediction 2 only had a 65% confidence that there was a woman at the location. Ideally, it should have predicted 100%.
Summary:
To summarize, we now know how to measure how well the object detector localizes objects, through bounding box regression and also how well the object detector predicts correct classes of localized objects, through cross-entropy loss.
During training of an object detector, the model’s internal parameters will be continuously adjusted by calculating the bounding box regression and cross-entropy loss again and again for a large number of annotated images and back-propagating the losses into the model. The lower the bounding box regression becomes, the better the model is at localizing objects and the lower the cross-entropy loss becomes, the better the model is at predicting the correct classes of the localized objects.
To get an even better idea of how object detectors learn, one would have to look into how back-propagation and stochastic gradient descent work. But we hope this post gave some brief intuition about how object detectors are able to learn due to their loss-functions.
Thank you for reading! Please upvote and/or leave a comment below if you found this post interesting
Get back to my other posts here