Recently, I have grown a big interest in various learning methods, for deep learning models, which tries to utilize unlabeled data such as semi-supervised learning and self-supervised learning. I am definitely not the only one. The topics are more generally called representation learning and it is receiving a great deal of attention in the deep learning research community these days.
The reason for the attention is quite obvious. So much data is being generated every second of every day on the internet. Basically, an unlimited stream of videos, messages, audio is being generated on e.g., YouTube, Spotfiy, Twitter, Wikipedia, Github, Facebook etc. Learning methods which are able to utilize just a tiny proportion of the unlimited pool of unlabeled raw data, will undoubtedly be superior to supervised learning approaches, which are limited learn from annotated data.
This post is a short summary of a really great paper from Google Research called 'FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence' or simply FixMatch. The approach achieves some very impressive results. It is for instance able to achieve a 78% accuracy on CIFAR-10 with only one labeled example per class! The paper build ontop of two previously-know methods called Pseudo-labeling and consistency regularization, which are summarized below.
The full paper can be found here: https://arxiv.org/pdf/2001.07685.pdf
Semi-supervised Learning
We won’t go into the details on semi-supervised learning in general in this summary, but the main motivations behind semi-supervised learning are the following:
- Labeled datasets are expensive to produce
- Raw unlabeled data is cheap
The goal of semi-supervised is basically to learn how to make use of the unlabeled raw data with the help of a small labeled dataset. Thereby, combining supervised learning and unsupervised learning.
Pseudo-labeling:
The method of pseudo-labeling is summarized in the following 4 steps:
- Train a deep learning model on a small labeled dataset (this is supervised learning)
- Used the model to make predictions on unlabeled samples
- All the samples which the model has a great prediction confidence (above some threshold) in are added to the train dataset together with their pseudo-labels
- Go back to step 1
How pseudo-labeling should work ideally:
Firstly, we start off with a small labeled data set and train a model to be able to predict them correctly.
Secondly, we use the trained model to make prediction on raw unlabeled data and add the ones it is most confident about to the train dataset
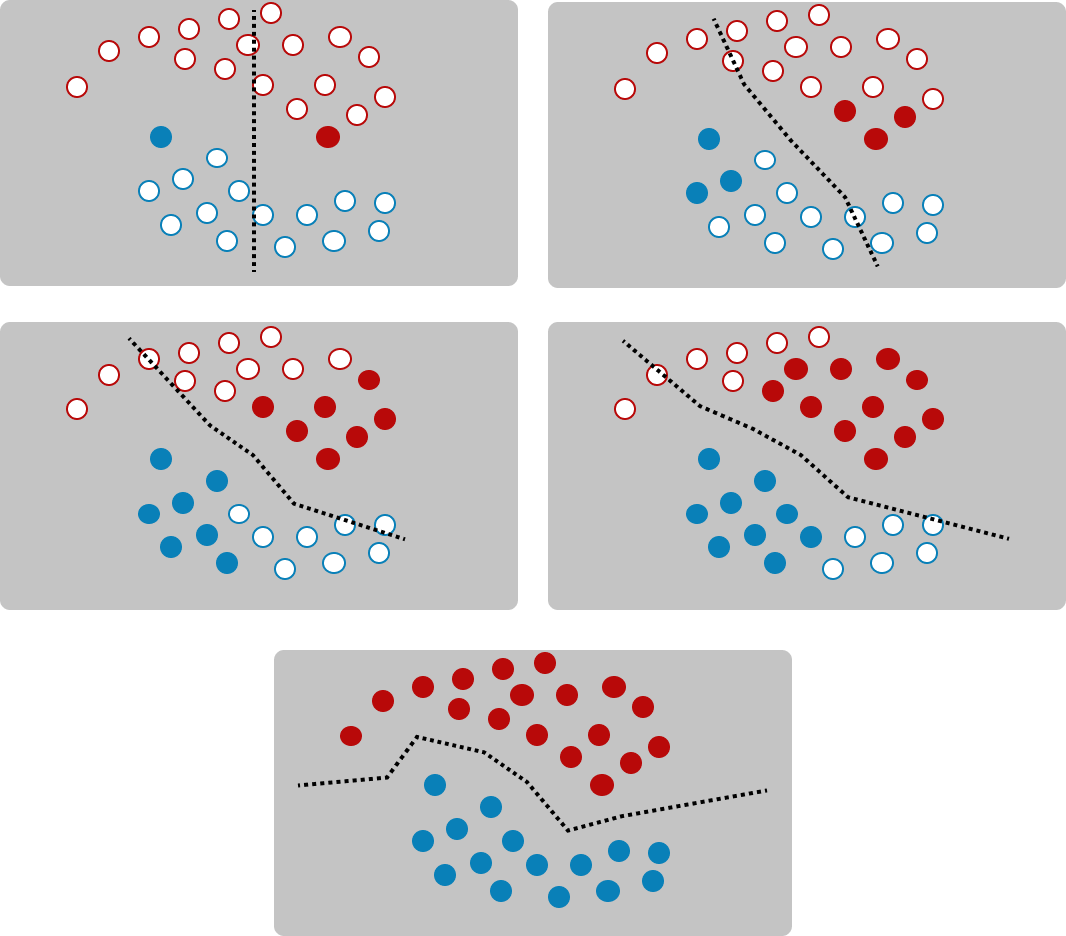
The training dataset continue to increase in size and the model will be able to predict more and more unlabeled samples correctly.
How pseudo-labeling works in reality:
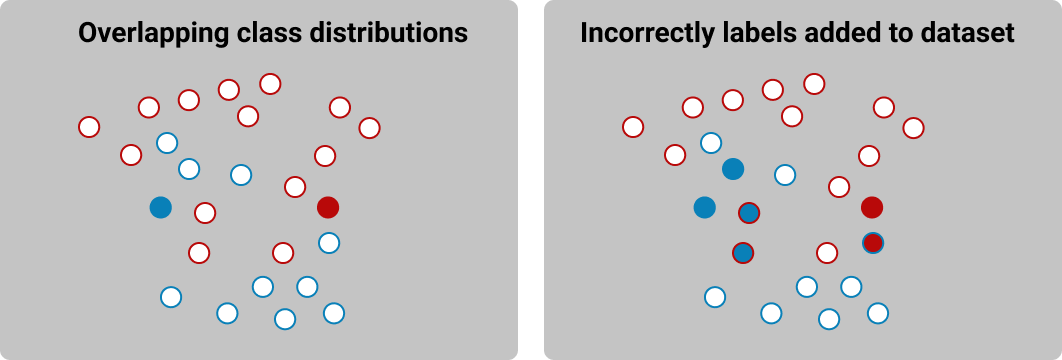
- Classes are almost never nicely separated in feature-space. Sometimes they even overlap
- Incorrectly predicted pseudo-labels are going to mess with the model. The model will learn from incorrectly labeled data and eventually start make even more incorrect predictions.
Consistency Regularization:
The method of consistency regularization is summarized in the following 3 steps:
- Select a sample from the unlablled dataset
- Apply two random augmentations to the sample
- Enforce that the model makes the same prediction for both augmentations
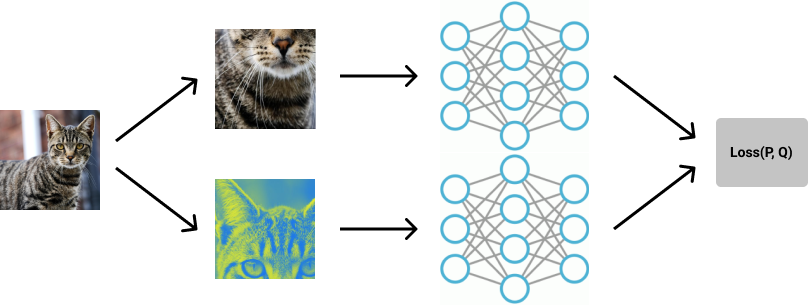
The FixMatch approach:
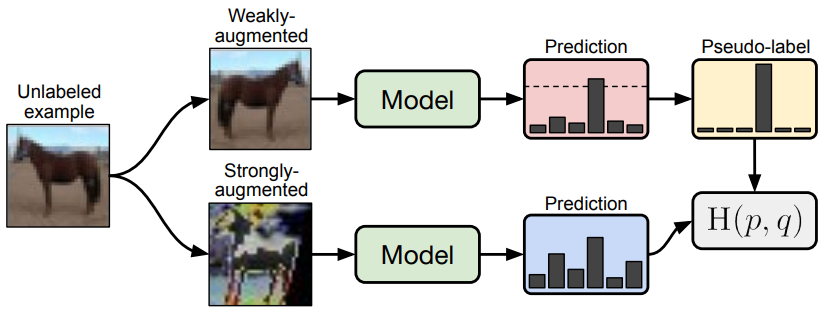
Now the two methods of pseudo-labeling and consistency regularization are combined into a joint method summarized in the following figure:

Text from paper:
- A weakly-augmented image (top) is fed into the model to obtain predictions (red box). When the model assigns a probability to any class which is above a threshold (dotted line), the prediction is converted to a one-hot pseudo-label.
- We then compute the model’s prediction for a strong augmentation of the same image (bottom). The model is trained to make its prediction on the strongly-augmented version match the pseudo-label via a cross-entropy loss"
The problems of FixMatch:
There are still problems and challenges to overcome. Some problems which still arise are the following:
- The model might never be able to make confident predictions on difficult classes. The model will never have a chance to learn the difficult classes
- Prototypicallity - If the initial labeled training samples does not capture the class distributions well, this might lead to the model making incorrect predictions to unlabelled samples
- The availability of raw unlablled data
Thank you for reading! Please upvote and/or leave a comment below if you found this post interesting
Get back to my other posts here